MSc Thesis Defence · University of Amsterdam
Stable-edge filtering for passive device-class classification in OT networks under operational change
Jonathan van den Heuvel · supervisors dr. Cyril Hsu & dr. Chrysa Papagianni
System & Network Engineering × KPMG Cyber · 7 July 2026
The setting
Operators need to know what is on their OT network, without touching it
- Operational-technology networks run power grids, water plants, factories
- Asset visibility is a prerequisite for segmentation, patching, and IEC 62443 / NIS2
- Active scanning can disturb the physical process, so it is risky in OT
- Passive traffic analysis is the pragmatic default: classify devices from the traffic a tap already sees
This work is hosted by KPMG's OT-security practice, where operational traces are never a clean steady state: laptops connect and disconnect, scanners sweep, configurations drift. A classifier that does well on a curated one-hour capture is not yet evidence it will behave when those things happen.
The idea under test
Real traffic mixes stable links with transient ones, so clean the graph first?
- A passive classifier works on the observed communication graph
- It mixes stable operational links (an HMI polling a PLC) with transient ones (engineering sessions, scans)
- A natural preprocessing step: keep only the edges that persist in time, the stable-edge filter
Research questions
Three questions operationalise the hypothesis
- RQ1Does the filter improve classification on steady-state traffic?
- RQ2Does it make classification of held-out hosts robust when their traffic changes?
- RQ3Where does the classification signal, and the filter's effect, live?
How devices are classified
A graph neural network reads each host and its neighbourhood
- Classifier: GraphSAGE, an inductive graph neural network, so it generalises to hosts unseen in training
- Each host has six features: in/out-degree, in/out-bytes, distinct source/destination ports
- Message passing aggregates a host's neighbours' features with its own; two layers reach the 2-hop neighbourhood
- A graph-free random forest on the same features is the graph-versus-no-graph reference
Prior passive OT classifiers take the observed graph as given, or prune edges that are rare in aggregate. None treats temporal persistence, whether an edge recurs across time windows, as the filter, and none tests robustness to operational change. That is the gap this thesis addresses.
The testbed
A reproducible OT lab with edge-level ground truth
- 20 always-on hosts, five device classes, four per class
- Modbus/TCP and S7 control traffic; HTTP and DNS on IT endpoints
- One passive tap on a shared segment, no active scanning
- Steady state plus four scripted change scenarios, with edge-level ground truth
- Seeded, fingerprinted, released for reproduction
- controller
- PLC · Modbus/S7 · polled
- supervisory
- HMI · polls controllers
- engineering
- workstation · sessions
- historian
- periodic snapshots
- IT endpoint
- HTTP / DNS
scenarios: maintenance, onboarding, configuration drift, benign noise
Filter + evaluation
Observation-window persistence, evaluated on hosts the model never saw
- An edge is kept if it is present in at least a fraction θ of the windows of the captured trace: the realistic passive case, where a single tap cannot segment phases
- Train on steady-state only; apply without retraining under change
- Host-stratified inductive split: 3 train + 1 held-out host per class, redrawn each seed
- 10 lab × 10 model seeds; paired Wilcoxon within seed
RQ1 · steady state
On stationary traffic the filter does nothing, and the graph adds nothing
- The filter removes zero edges from a stationary phase, so RQ1 is a sanity check, not a comparison
- A graph-free random forest is at least as accurate as GraphSAGE on held-out hosts (paired p = 0.037)
- So the classification signal lives in the host features, which makes the maintenance finding classifier-independent
RQ2 · robustness under change
No benefit anywhere, and a significant penalty under maintenance
0.45 → 0.36 Δ −0.089 · p = 0.027 · worse 8/10 seeds
Neutral on four of five scenarios; significantly harmful in the one containing a genuine equipment outage. The filter delivers no robustness benefit, and a real cost.
Why maintenance breaks it
A paused controller, stripped of its polls, looks like an idle IT endpoint
- 1During the 40-min outage the polls fall to 22/30 = 73% < θ
- 2The filter cuts them from every window: in-degree 20→0, in-bytes 2.1M→0
- 3The feature vector collapses, and is misread as an idle IT endpoint
Is it real?
Controls isolate the cause
- Random, same count removed → harmless. So it is not that removing edges hurts.
- Byte-volume → also harmful. A second content-blind proxy strips the low-volume polls.
- Phase-local (the idealised filter) → removes nothing. The penalty is the observation window.
Ruling out confounds
Not distribution shift; concentrated on the paused host
- Train on sparsified graphs? penalty persists, Δ −0.126 so it is feature destruction, not a dense-train / sparse-test shift
- Leave-one-controller-out plc-1 (paused) −0.229 vs others ~−0.037 a clean per-controller estimate; the effect tracks the paused host
- Classifier-independent random forest shows the same −0.104 not an artefact of graph aggregation
RQ3 · where the signal lives
Node-local features carry the signal, and take the damage
- Node-local features alone (bytes, ports) generalise as well as the full set (0.505 vs 0.490)
- The neighbourhood degree features raise the training fit but not held-out generalisation
- The maintenance penalty appears under both feature subsets
Filtering the polls into the paused controller zeroes its degree features and its byte and port features at once, because in this lab a controller's entire observable footprint is the polls it receives. The harm is feature destruction, which is why a classifier with no graph aggregation suffers it too.
The contribution
Content-agnostic edge filtering is fragile for passive OT classification.
A controller's class-defining inbound polls are both low-volume and event-sensitive, so multiple natural proxies (observation-window persistence, byte-volume) preferentially strip them; a count-matched random removal does not, but is useless as a denoiser. A useful filter must be content / semantics-aware.
From negative result to design principle
A content-aware filter removes the failure mode
- Keep any edge to a control-protocol port (Modbus, S7) regardless of persistence; apply the persistence test only to the rest
- Under maintenance it removes no edges, so the penalty disappears: Δ +0.000 vs −0.089
- It still prunes the benign-noise scanner edges, so it is selective, not disabled
What it claims, and what it doesn't
- The magnitude is specific to this lab's near-bipartite poll topology
- In a field plant a paused PLC keeps peer and historian traffic, so the collapse would be partial
- One observation point, five device classes, a fixed window length
What is expected to transfer
- The mechanism: content-agnostic proxies strip low-volume, event-sensitive class-defining edges
- Supported by byte-volume reproducing the harm through a different proxy
- Field validation on a real trace is the primary next step
Contributions
- A reproducible OT lab with five device classes, four operational-change scenarios, and edge-level ground truth, released with all code
- The finding, with controls, that content-agnostic edge filtering is fragile, established inductively over 10 × 10 seeds and classifier-independent
- A content-aware remedy that removes the failure mode and turns the negative result into a design principle
Future work
- A learned content-aware edge filter, using the lab's edge-level labels
- Validation on a real, NDA-constrained OT trace
- A window-length sweep; generalisation to unseen classes and topologies
In one line
A content-agnostic filter strips the edges that define a controller; a content-aware one does not.
Jonathan van den Heuvel · University of Amsterdam · 2026
Thank you. Questions?
Backup
Backup slides, for questions.
Graph utility · distribution shift · external validity · the control table · the confusion matrix · the θ sweep.
Backup · graph utility
"Why a graph thesis if the graph adds nothing?"
- RF 0.512 vs GraphSAGE 0.490 on held-out hosts (paired p = 0.037)
- Treat it as a result: the graph adds no accuracy at this scale (20 hosts, 4 per class, 6 features)
- The maintenance penalty reproduces in the random forest, so it is feature destruction, not a message-passing artefact
- That makes the finding hold for any classifier reading the features, which is more robust, not less
Backup · distribution shift
"Isn't it just train-dense / test-sparse shift?"
- The filter removes nothing from steady state, so the filtered model trains on dense graphs and tests on sparse ones
- Control: train on randomly-sparsified steady-state graphs, so the model has seen sparse neighbourhoods, then test on filtered maintenance
- The penalty persists, Δ −0.126, so it is not pure covariate shift
- A direct retrain-on-filtered control would settle it completely, and is future work (stated honestly)
The count-matched random removal also argues against pure sparsity: equal test-time edge density, but no harm. Two controls point the same way; one is still left open, and the talk does not over-claim closure.
Backup · external validity
"n = 1 lab, n = 1 paused controller, isn't the failure engineered?"
- The magnitude is manufactured by the near-bipartite topology, conceded
- In a real plant a paused PLC keeps peer, historian, and management traffic, so the collapse is partial and the penalty smaller
- The mechanism is the claim, and a different proxy (byte-volume) reproduces it
- The bipartite simplification is a stated scope condition on the headline, not a hidden assumption
The split between magnitude (lab-specific, concede it) and mechanism (general, defend it) is the move for every external-validity question. Field validation on a real trace is the primary future work.
Backup · the numbers
Maintenance Δ by selection rule
All 10 lab × 10 model seeds, paired Wilcoxon. Same count of edges removed per window; only rules that target the low-volume polls are harmful.
- stable-edge (persistence) −0.089p = 0.027 · worse 8/10 · the thesis filter
- byte-volume −0.060p = 0.004 · worse 9/10 · also harmful
- random count-matched +0.051p = 0.16 · harmless, rules out "any removal"
- phase-local 0.000removes nothing by construction · the penalty is the window
- content-aware +0.000the fix: keeps the polls, still prunes scanners
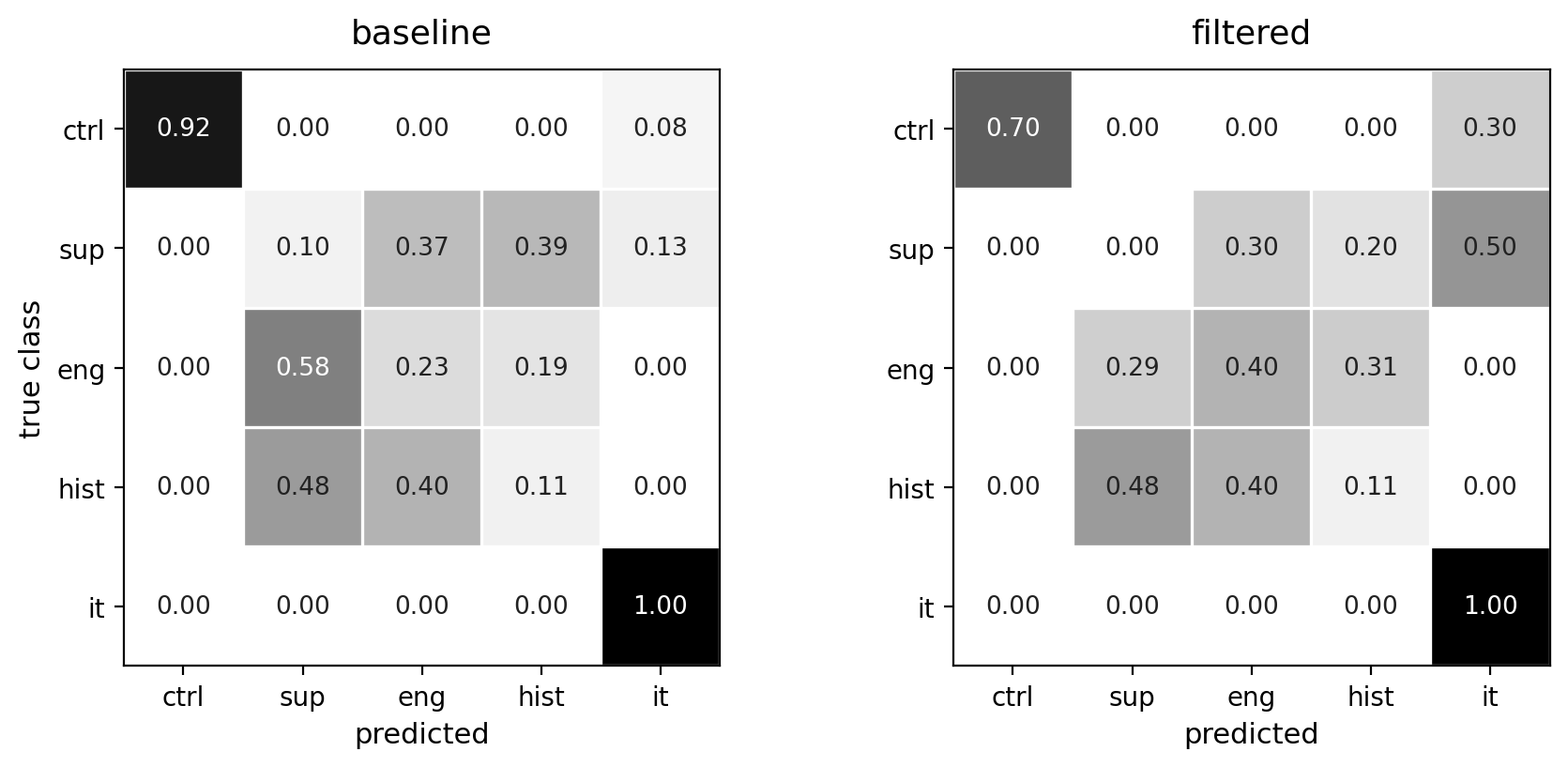
Backup · the misclassification
Filtering shifts the paused controller toward "IT endpoint"
- Controller recall (the diagonal) falls 0.92 → 0.70
- 0.30 of controller windows leak to it (the ctrl→it cell rises 0.08 → 0.30)
- High precision keeps controller F1 at 0.82, not 0: only the paused host's windows flip
Backup · operating point
The penalty holds at every threshold that removes edges
- θ swept from 0.3 to 0.9, window length fixed at 5 minutes
- Harmful at every θ that removes anything; beneficial at none
- So the result is not an artefact of the default operating point